多线程基础-JMM-volatile
多线程并发中的关键问题(包括有序性、可见性和原子性),Java 内存模型(JMM)的核心原理,深入剖析了,及 volatile 关键字。
多线程基础-JMM-volatile
背景
从 Java 代码到 CPU 指令的变化过程是怎样的?
我们在 Java 代码中,使用的控制并发的手段例如 synchronized 关键字,最终也是要转化为 CPU 指令来生效的,从 Java 代码到最终执行的 CPU 指令的流程大致如下:
最开始,我们编写的 Java 代码,是 *.java 文件,
在编译(javac 命令)后,从刚才的 *.java 文件会变出一个新的 Java 字节码文件(*.class),
JVM 会执行刚才生成的字节码文件(*.class),并把字节码文件转化为机器指令。
机器指令可以直接在 CPU 上运行,也就是最终的程序执行,而 不同的 JVM 实现会带来不同的 “翻译”,不同的 CPU 平台的机器指令又千差万别。
所以我们在 java 代码层写的各种 Lock,其实最后依赖的是 JVM 的具体实现(不同版本会有不同实现)和 CPU 的指令,才能帮我们达到线程安全的效果。
由于最终效果依赖处理器, 不同处理器结果不一样, 这样无法保证并发安全,所以需要一个标准,让多线程运行的结果可预期,这个标准就是 JMM。
为何需要 JMM (Java 内存模型)?
跨平台并发的问题:底层硬件与虚拟机的实现差异,导致统一的并发控制变得极其困难
引入 JMM (Java 内存模型) 标准
正因底部环境极其复杂多变,我们编写的 Lock 无法直接、稳定地运行在各类机器上。
因此需要 JMM 作为一层统一的标准规范,屏蔽各类 JVM 和操作系统的内存访问差异,
让 Java 开发者无需关心底层细节,即可实现"一次编写,到处安全并发"。
JMM 篇
JMM 全称 Java Memory Model,也叫 Java 内存模型。
JMM 是一组 规范,需要各个 JVM 的实现来遵守 JMM 规范,以便于开发者可以利用这些规范,更方便地开发多线程程序。
JMM 也是工具类、关键字的原理,比如 volatile、synchronized、lock 等。
并发问题的根源
并发三要素: 有序性(重排序引起的问题)、可见性、原子性
重排序
简单来说,就是指在程序中写的代码,并不一定按照写的顺序去执行时(说实话,我第一次听到这个的时候都惊了😅)。
重排序例子
public class OutOfOrderExecution {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for (; ; ) {
i++;
x = 0;
y = 0;
a = 0;
b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();
other.start();
one.join();
other.join();
String result = "第 " + i + " 次 (" + x + "," + y + ")";
if (x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
}
让代码跑起来,要跑出来需要的时间挺长!尤其是你的电脑运算速度越快,那么时间可能会更长 :) 甚至十几分钟!
比如我的:第 5198378 次 (0,0),跑了快 520 万次。
代码分析
Note
定义了 4 个变量:x、y、a、b
2 个线程:one、other
完整执行的情况:
情况 1:
-
先执行 one,a = 1, x = b 此时 x = 0
-
再执行 other, b = 1, y = a (y = 1), 第一步 a 已经等于 1 了
-
结果: x = 0, y = 1
情况 2:
-
先执行 other, b = 1, y = a 此时 y = 0
-
再执行 one, a = 1, x = b (x = 1), 第一步 b 已经等于 1 了
-
结果: x = 1, y = 0
非完整、穿插执行情况:
情况 3:
-
先执行 one 的 a = 1, (x = b) 不执行
-
再执行 other 的 b = 1, (y = a) 不执行
-
再执行 one 的 x = b, 这时 x = 1
-
再执行 other 的 y = a, 这时 y = 1
-
结果: x = 1, y = 1
情况 4:
-
先执行 one 的 a = 1, (x = b) 不执行
-
再执行 other , b = 1, y = a 此时 y = 1
-
再执行 one 的 x = b, 此时 x = 1
-
结果: x = 1, y = 1
所以,理论上是不会出现 x = 0, y = 0 的情况!
但是 如果发生重排序了,极端的情况:
-
先执行 one 的 x = b, (a = 1) 不执行,此时 x = 0
-
再执行 other 的 y = a, (b = 1) 不执行, 此时 y = 0
-
再执行 a = 1 和 b = 1 (先执行哪个已经不重要了)
-
结果就是: x = 0, y = 0
重排序发生的 3 种情况
- 编译器优化
编译器(包括 JVM,JIT 编译器等)出于优化的目的(例如当前有了数据 a,那么如果把对 a 的操作放到一起效率会更高,避免了读取 b 后又返回来重新读取 a 的时间开销),在编译的过程中会进行一定程度的重排,导致生成的机器指令和之前的字节码的顺序不一致。
在上述的例子中,编译器将
y=a和b=1这两行语句换了顺序(也可能是线程 2 的两行换了顺序,同理),因为它们之间没有数据依赖关系,那就不难得到x =0,y = 0这种结果了。 - 指令重排序 CPU 的优化行为,和编译器优化很类似,是通过乱序执行的技术,来提高执行效率。所以就算编译器不发生重排,CPU 也可能对指令进行重排,所以我们开发中,一定要考虑到重排序带来的后果。
- 内存的“重排序” 内存系统内不存在重排序,但是内存会带来看上去和重排序一样的效果,所以这里的 “重排序” 打了双引号。由于内存有缓存的存在,在 JMM 里表现为主存和本地内存,由于主存和本地内存的不一致,会使得程序表现出乱序的行为。 在上述的例子中,假设没编译器重排和指令重排,但是如果发生了内存缓存不一致,也可能导致同样的情况:线程 1 修改了 a 的值,但是修改后并没有写回主存,所以线程 2 是看不到刚才线程 1 对 a 的修改的,所以线程 2 看到 a 还是等于 0。同理,线程 2 对 b 的赋值操作也可能由于没及时写回主存,导致线程 1 看不到刚才线程 2 的修改。
什么是 JMM 里面的主内存和本地内存?
Java 作为高级语言,屏蔽了 CPU 多层缓存 这些底层细节,用 JMM 定义了一套读写内存数据的规范,虽然我们不再需要关心 一级缓存 和 二级缓存 的问题,但是,JMM 抽象出了 主内存 和 本地内存 的概念。
这里说的本地内存并不是真的是一块给每个线程分配的内存,而是 JMM 的一个抽象,是对于寄存器、一级缓存、二级缓存等的抽象。
主内存和本地内存关系图示
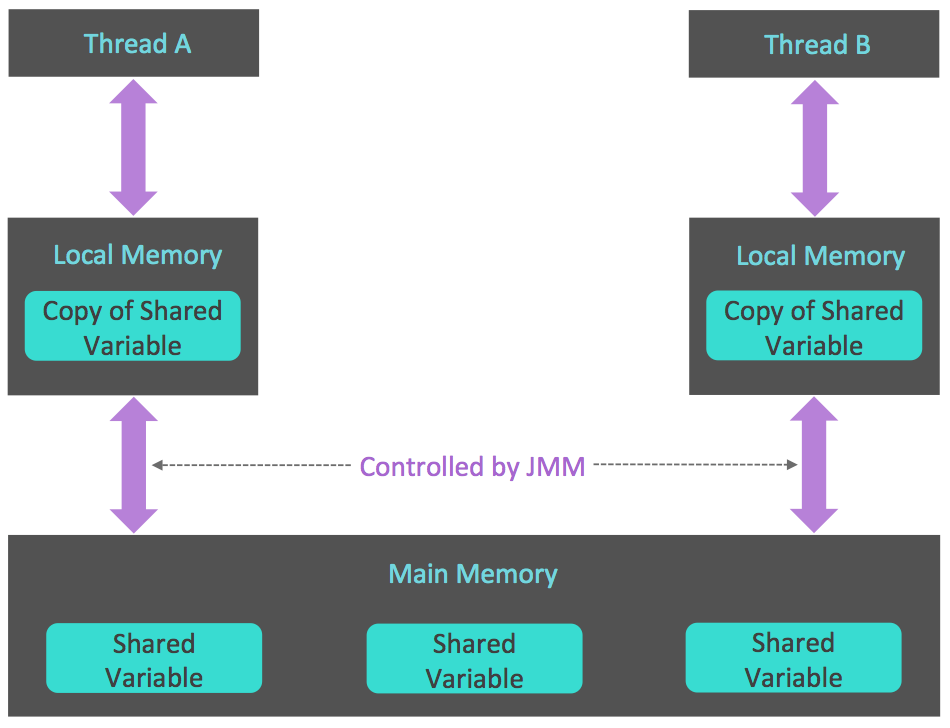
JMM 有以下规定:
- 所有的变量 都存储在 主内存 中,同时 每个线程 也有自己 独立的工作内存,工作内存中的变量内容是主内存中的 拷贝(副本)。
- 线程 不能直接读写主内存中的变量, 而是只能 操作自己工作内存中的变量,然后再 同步 到主内存中。
- 主内存 是 多个线程共享 的,但 线程间不共享工作内存, 如果线程问需要通信,必须借助 主内存中转 来完成。
Important
所有的 共享变量存在于主内存 中,每个线程有 自己的本地内存,而且 线程读写共享数据也是通过本地内存 交换的,所以才导致了 可见性问题。
线程可见性问题
例子
public class FieldVisibility {
private int a = 1;
private int b = 2;
private void change() {
a = 3;
b = a;
}
private void print() {
System.out.println("b=" + b + ",a=" + a);
}
public static void main(String[] args) {
for (; ; ) {
FieldVisibility visibility = new FieldVisibility();
new Thread(() -> {
visibility.change();
}).start();
new Thread(() -> {
visibility.print();
}).start();
}
}
}
代码分析
Note
我们给 FieldVisibility 定义了两个变量: a = 1, b = 2
同时我们提供了 2 个方法: change()、print()
change() 方法的作用,是修改 a、b 变量的值,a = 3, b = a
print() 方法的作用,是打印出 a、b 变量的值
下面就是在 main 方法中,启动 2 个线程,分别去执行 change() 方法和 print() 方法。
情况 1:
第 1 个线程先执行 change(),将 a = 3, b = a, b 也重新改为 3,执行完成后,第 2 个线程再执行 print(),打印出: b = 3, a = 3
情况 2:
第 2 个线程先执行 print(),打印出: b = 2, a = 1,执行完成后,第 1 个线程再执行 change()
情况 3:
第 1 个线程先执行 change(),将 a = 3 已执行, b = a 还没执行,然后第 2 个线程再执行 print(),打印出: b = 2, a = 3
⚠️ 实际还有一个情况 4:
第 1 个线程先执行 change(),将 a = 3, b = a, b 也重新改为 3,执行完成后,第 2 个线程再执行 print(),但是却打印出: b = 3, a = 1!!!
正常来说,怎么样都不会出现 b = 3, a = 1 的情况呀!但实际确实是出现了!这其实就是线程可见性导致的。
private void change() {
a = 3;
b = a;
}
change() 方法是执行完了,a = 3,b 也改为 3 了,这些操作都是在线程自己的本地内存修改的,但是 a = 3 的值还没有写回去 主内存,另一个线程执行 print() 方法的时候,读取 a 的值,依然是主内存的 1,所以就出现了 b = 3, a = 1 。
解决办法
上面的例子如何修改?
我们给 a、b 变量加上 volatile 修饰就可以了
private volatile int a = 1; private volatile int b = 2;实际只需要给 1 个变量 b 加 volatile 就可以了,
b=a因为要读取 a,所以b = a这之前的语句操作其实调用change()也都能看到,从而保证 a 的值也是最终修改后的。
Tip
经过上面的例子, 其实涉及到一个知识:happens-before ,可参考文章末尾内容
volatile 关键字
volatile 是一种同步机制,比 synchronized 或者 Lock 相关类更轻量,因为使用 volatile 并不会发生上下文切换等开销很大的行为。
volatile 作用
- 禁止指令重排序:禁止指令重排序优化,典型的例子就是 单例双重检查锁乱序问题!
- 保证线程可见性:读 一个 volatile 变量之前,需要先 让相应的本地缓存失效,这样就必须去 主内存中读取最新值;写 一个 volatile 变量属性会立即 刷入主内存。
volatile 适用场合
首先不适用:i++; 因为 i++ 是个非原子操作! 所以即使用了 volatile 也不能保证原子性。
使用 volatile 所需的条件
Important
- 对变量的写操作不依赖于当前值(大多数使用都是该场景)。
- 该变量没有包含在具有其他变量的不变式中。
- 只有在状态真正独立于程序内其他内容时才能使用 volatile。
demo 场景:状态标志(不方便理解可参考下面具体场景一)
场景:状态标志
使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。
volatile boolean shutdownRequested; ...... // 对变量仅有直接赋值的操作 // thread A public void shutdown() { destory(); shutdownRequested = true; } // thread B , thread A 改变标记后,能立刻让 thread B 感知到 public void doWork() { while (!shutdownRequested) { // do stuff } }上述例子中,如果将
shutdownRequested = true;换成shutdownRequested = !shutdownRequested;就不适用了。
volatile 的使用场景其实非常有限且特定,只需要记住 三个核心场景 即可。
如果你的需求超出了这三个场景,大概率你应该使用 synchronized 或 Atomic 类。
场景一:状态标记量 (Status Flags) —— 最经典用法
这是 volatile 最常用的场景。通常用于一个线程控制另一个线程的 开始/暂停/停止。
特点:
- 不依赖当前值(即不是
count = count + 1这种累加操作)。 - 状态只有 true/false 或固定数值。
代码示例:
public class TaskRunner implements Runnable {
// 必须加 volatile,保证 shutdown() 被调用时,run() 方法能立刻感知
private volatile boolean shutdown = false;
public void shutdown() {
this.shutdown = true;
}
@Override
public void run() {
while (!shutdown) { // 读操作
// 执行任务...
}
System.out.println("任务停止");
}
}
为什么这里不用 synchronized?
因为加锁太重了,我们只需要保证“主内存可见性”,不需要保证操作的“原子性”(赋值 true 本身就是原子的)。
场景二:安全发布 (Safe Publication) —— 比如单例模式
这就是我们最开始讨论的 双重检查锁(DCL)。
特点:
防止对象在初始化未完成时,被其他线程拿到引用(防止指令重排序造成半成品对象)。
代码示例:
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
// 如果没有 volatile,这里可能发生重排序,导致返回一个没初始化的对象
instance = new Singleton();
}
}
}
return instance;
}
场景三:开销较低的“读写锁”策略
如果你有大量的 读操作,只有极少量的 写操作,你可以结合使用 volatile 和 synchronized。
策略:
- 读操作:不加锁,直接读
volatile变量(性能极高)。 - 写操作:加
synchronized锁(保证原子性)。
代码示例(一个简单的计数器):
public class CheesyCounter {
// volatile 保证读操作能看到最新的值
private volatile int value;
// 读操作:无锁,极其快
public int getValue() {
return value;
}
// 写操作:加锁,保证原子性(比如防止两个线程同时 +1 导致丢失更新)
public synchronized void increment() {
value++;
}
}
注意:这种写法的前提是,increment 这种修改状态的操作必须是互斥的,但读取可以并发。
绝对不要用的场景:依赖当前值的计算(如 i++)
这是面试和实际开发中最大的坑。
错误示范:
public class Counter {
private volatile int count = 0;
// 错误!volatile 不能保证原子性
public void add() {
count++;
}
}
为什么不行?
count++ 实际上包含了三步指令:
- Read: 读取 count (0)
- Modify: 计算 0 + 1
- Write: 写入 count (1)
如果有两个线程同时进入,它们可能都读到 0,都计算出 1,都写入 1,导致做了两次加法,结果却只加了 1。
修正方案:使用 AtomicInteger 或 synchronized。
总结
当犹豫是否该用 volatile 时,考虑两个问题:
- 对变量的写入,是否依赖它当前的值?
- 是(如
count++,flag = !flag) -> 不能用 volatile(除非像场景三那样配合锁)。 - 否(如
flag = true,value = 5) -> 可以用。
- 是(如
- 该变量是否包含在具有其他变量的不变式中?
- 是(如
start < end,你想同时更新 start 和 end) -> 不能用 volatile(volatile 只能保证单个变量的可见性,无法保证两个变量更新的原子性)。 - 否 -> 可以用。
- 是(如
简单来说:只有当你只是想简单地“通知”一下其他线程某个状态变了,而不需要进行复杂的逻辑计算时,才用 volatile。
volatile 和 synchronized 的关系
volatile 可以理解为 1 个轻量版的 synchronized。
volatile 是一个 字段修饰符,而 synchronized 可以修饰 代码块 和 方法。
volatile 只在线程的 本地内存 和 “主” 内存 之间 同步一个变量 的值,synchronized 在线程的 本地内存 和 “主” 内存 之间 同步所有变量 的值,并锁定和释放一个监视器。
显然,synchronized 的开销可能比 volatile 的开销更大。
原子性
即一系列的操作(一个操作或者多个操作),要么全部执行成功,要么就都不执行成功,不会出现执行一半成功的情况,是不可分割的。
Java 中默认提供的原子操作有哪些?
- 除了 long 和 double 之外的基本类型(int、 short、 float、 byte、 char、 boolean )的赋值操作。
比如:int i = 10; 就是原子操作。
- 所有引用 reference 的赋值操作
- java.concurrent.Atomic.* 包中所有类的原子操作
long 和 double 的原子性问题
因为 long 和 double 两种数据类型(64 位)的操作可分为两个 32 位的操作,高 32 位和低 32 位两部分,因此普通的 long 或 double 类型读 / 写可能不是原子的。
因此,官方也鼓励程序员,将共享的 long 和 double 变量设置为 volatile 类型,这样能保证无论它们是作为 32 位还是 64 位值实现的,对 long 和 double 的单次读 / 写操作都具有原子性。
不过,现在大部分电脑都是 64 位了,在 64 位的 JVM 上就是原子的,32 位上的 JVM 就需要考虑该问题了。
实际开发中:商用 Java 虚拟机中是不会出现这样的问题的,但是该知识要了解。
官网文档参考:17.7 https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html
JVM 内存结构 vs Java 内存模型 vs Java 对象模型
概括总结就是:
- JVM 内存结构:是 物理布局(数据放在哪?)
- Java 内存模型 (JMM):是 逻辑规则,规范(多线程怎么交互?)
- Java 对象模型:是 数据结构(对象在堆里长什么样?)
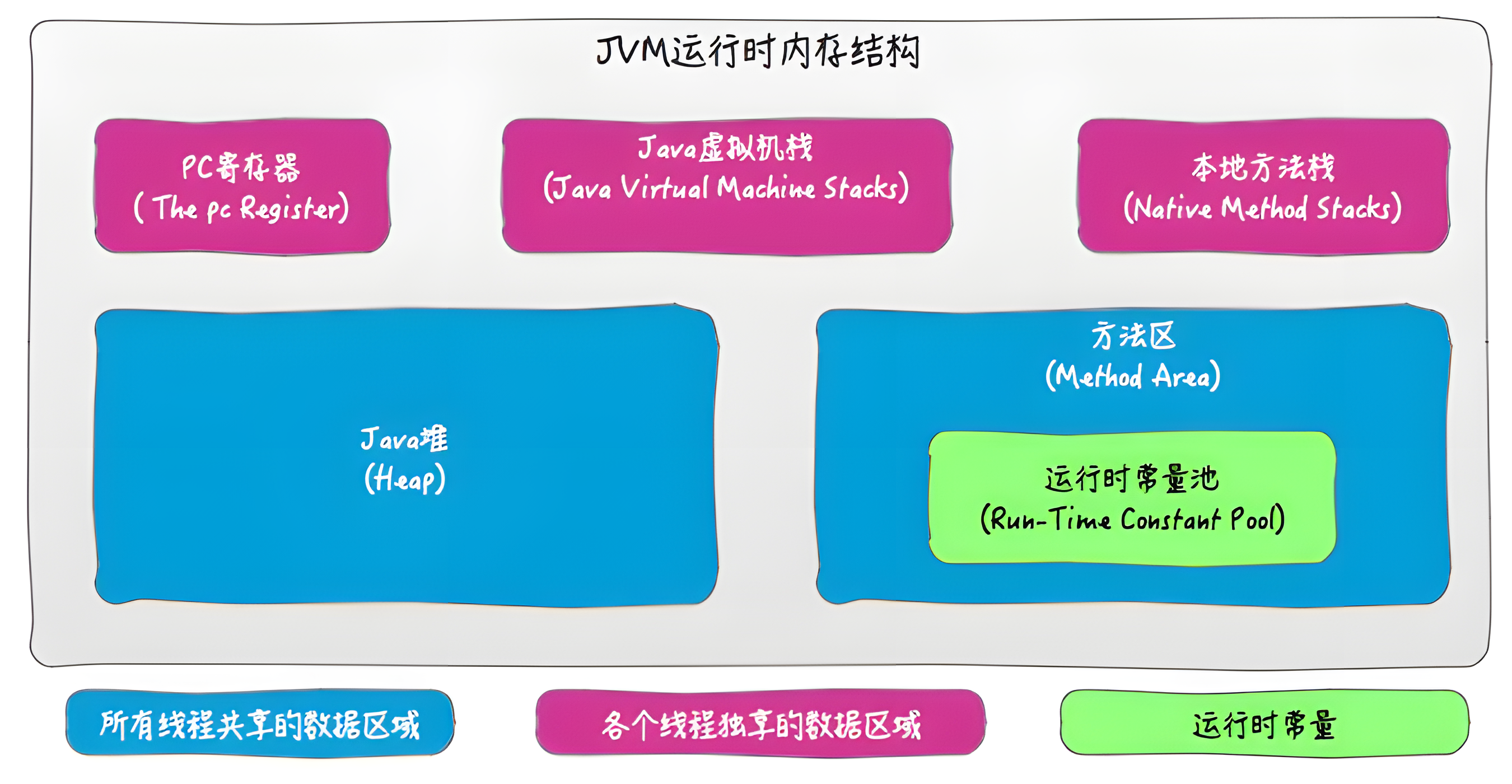
1. JVM 内存结构 (JVM Runtime Data Areas)
JVM 内存结构主要是: 存储位置。
这是 Java 虚拟机规范中定义的,JVM 在运行 Java 程序时,对内存进行的 功能性划分。也就是 JVM 在运行 Java 程序时如何划分内存区域。
主要组成以下几个部分
线程共享区域
- 堆 (Heap):存放对象实例(你的
new Object()都在这)。垃圾回收(GC)的主要区域。 - 方法区 (Method Area / Metaspace):存放类信息、常量、静态变量、JIT 编译后的代码。
线程私有区域
- 虚拟机栈 (VM Stack):描述 Java 方法执行的内存模型,每个方法执行都会创建一个栈帧(Stack Frame),包含局部变量表、操作数栈等。
- 本地方法栈 (Native Method Stack):为 Native 方法服务。
- 程序计数器 (PC Register):记录当前线程执行到哪一行字节码了。
2. Java 内存模型 (Java Memory Model, JMM)
JMM 主要是讲 并发安全(原子性、可见性、有序性)。
JMM 是一套 抽象的规范(JSR-133),它不对应物理内存,而是定义了 JVM 如何通过内存与 CPU 缓存(寄存器、L1/L2/L3)进行交互。它的目的是屏蔽掉各种硬件和操作系统的内存访问差异。
抽象视图
- 主内存 (Main Memory):所有变量都存在这里(类似于物理内存)。
- 工作内存 (Working Memory):每个线程私有的,保留了该线程使用到的变量的主内存副本(类似于 CPU 缓存)。
交互规则
- 线程不能直接操作主内存,必须先将变量 load 到自己的工作内存中,修改后再 save 回主内存。
- 这引发了多线程的 可见性 问题(也就是
volatile、synchronized试图解决的问题)。
3. Java 对象模型 (Java Object Model)
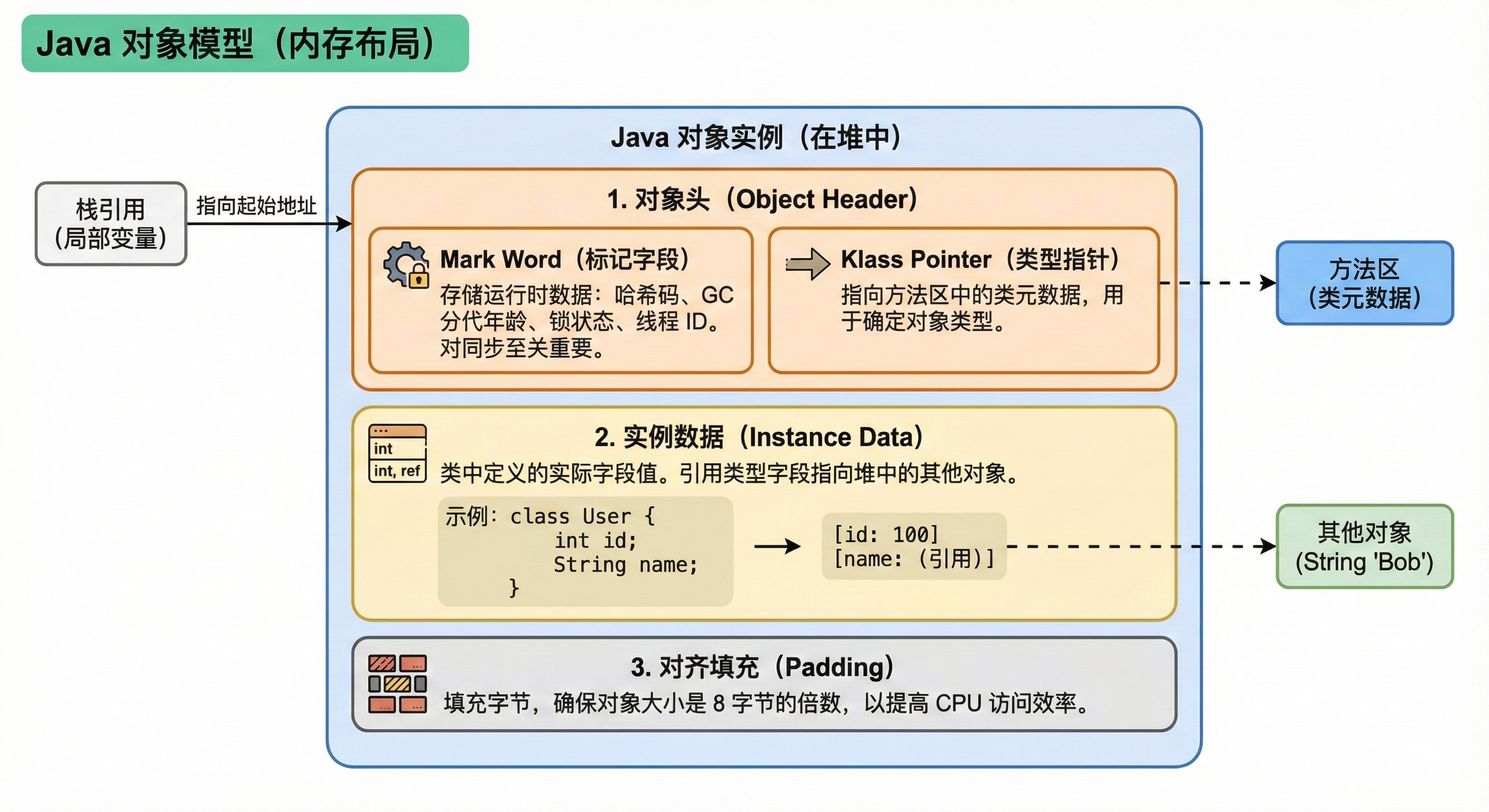
Java 对象模型讲的是 对象的内部布局。
这是指一个 Java 对象在 JVM 堆内存中具体的 二进制存储格式(HotSpot 虚拟机实现)。它决定了对象怎么引用类元数据,怎么在内存中对齐。
主要组成(以 HotSpot 为例)
- 对象头 (Header)
- Mark Word:存储运行时数据,如 HashCode、GC 分代年龄、锁状态标志(偏向锁/轻量级锁/重量级锁)、线程持有的锁等。这是并发编程中 synchronized 锁升级的基石。
- Klass Pointer (类型指针):指向方法区中的类元数据,确定这个对象是哪个类的实例。
- 数组长度:如果是数组对象,还需要记录数组长度。
-
实例数据 (Instance Data) : 对象真正存储的有效信息(即你在类中定义的各种字段内容,如
int age,String name)。 -
对齐填充 (Padding) : HotSpot 要求对象起始地址必须是 8 字节的整数倍,不够的话需要补齐(为了 CPU 读取性能)。
总结对比表
| 维度 | JVM 内存结构 | Java 内存模型 (JMM) | Java 对象模型 |
|---|---|---|---|
| 英文 | JVM Runtime Data Areas | Java Memory Model | Java Object Layout |
| 解决的问题 | 代码运行时的 空间分配 与管理 | 多线程并发下的 数据一致性 | 对象在底层的 表示与寻址 |
| 核心关键词 | 堆、栈、方法区、GC | 主内存、工作内存、volatile、可见性 | 对象头、Mark Word、指针压缩、Padding |
概括来说: 你在 JVM 内存结构 的“堆”中创建了一个对象,这个对象的结构遵循 Java 对象模型,当多个线程同时访问这个对象时,需要遵守 Java 内存模型 (JMM) 的规范来保证数据安全。
happens-before 规则
happens-before 规则
可以理解为:在时间上,动作 A 发生在动作 B 之前,B 保证能看见 A,这就是 happens-before。
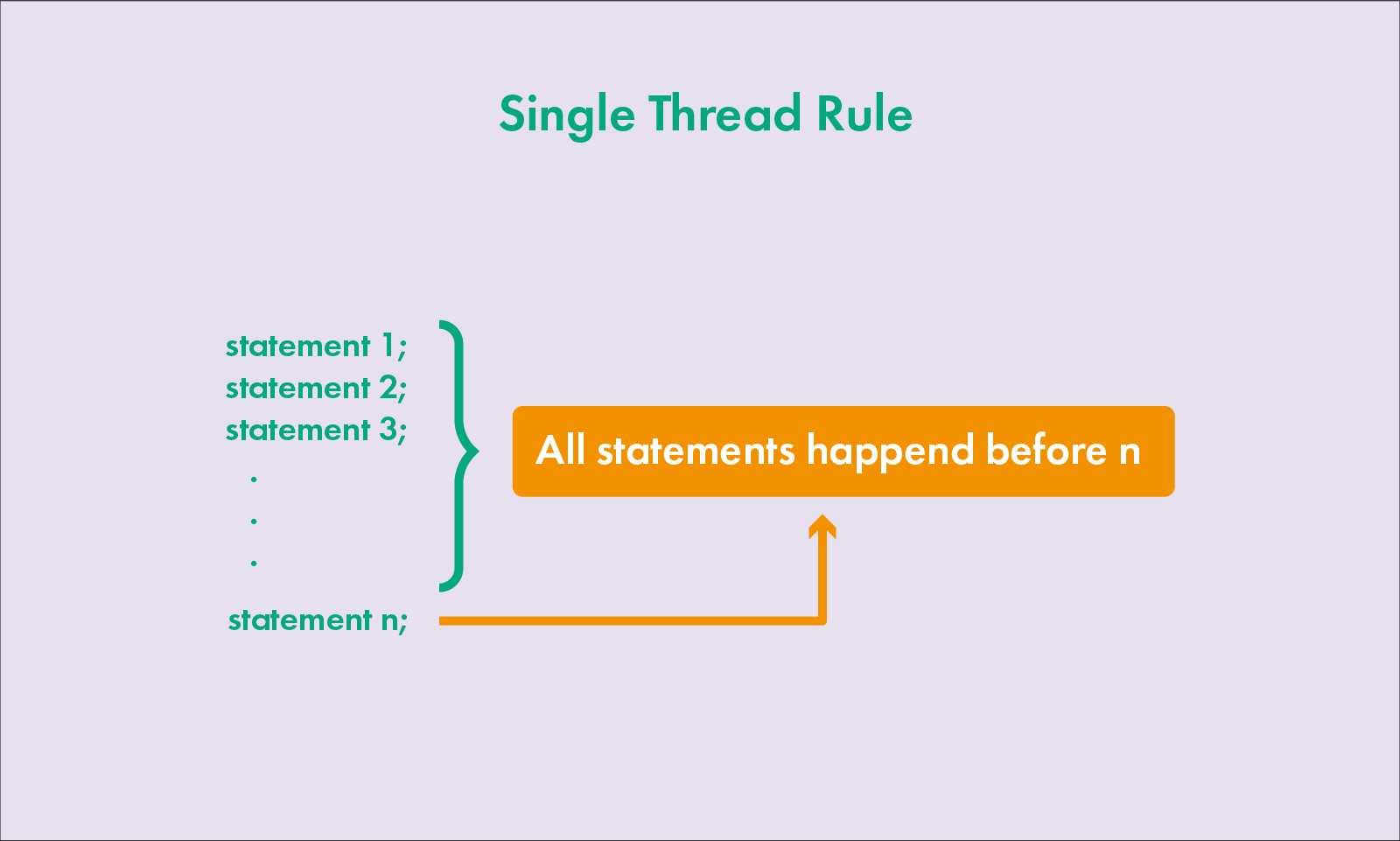
1. 单线程规则 Single Thread Rule
一个线程里,都遵守 Happens before(除了重排序,重排序是有前提的,必须是不相干的代码才能重排序,下面的示例就不会发生重排序)
比如:
private void change() {
a = 3;
b = a; // 执行语句时,一定会看到之前发生的 a = 3
}
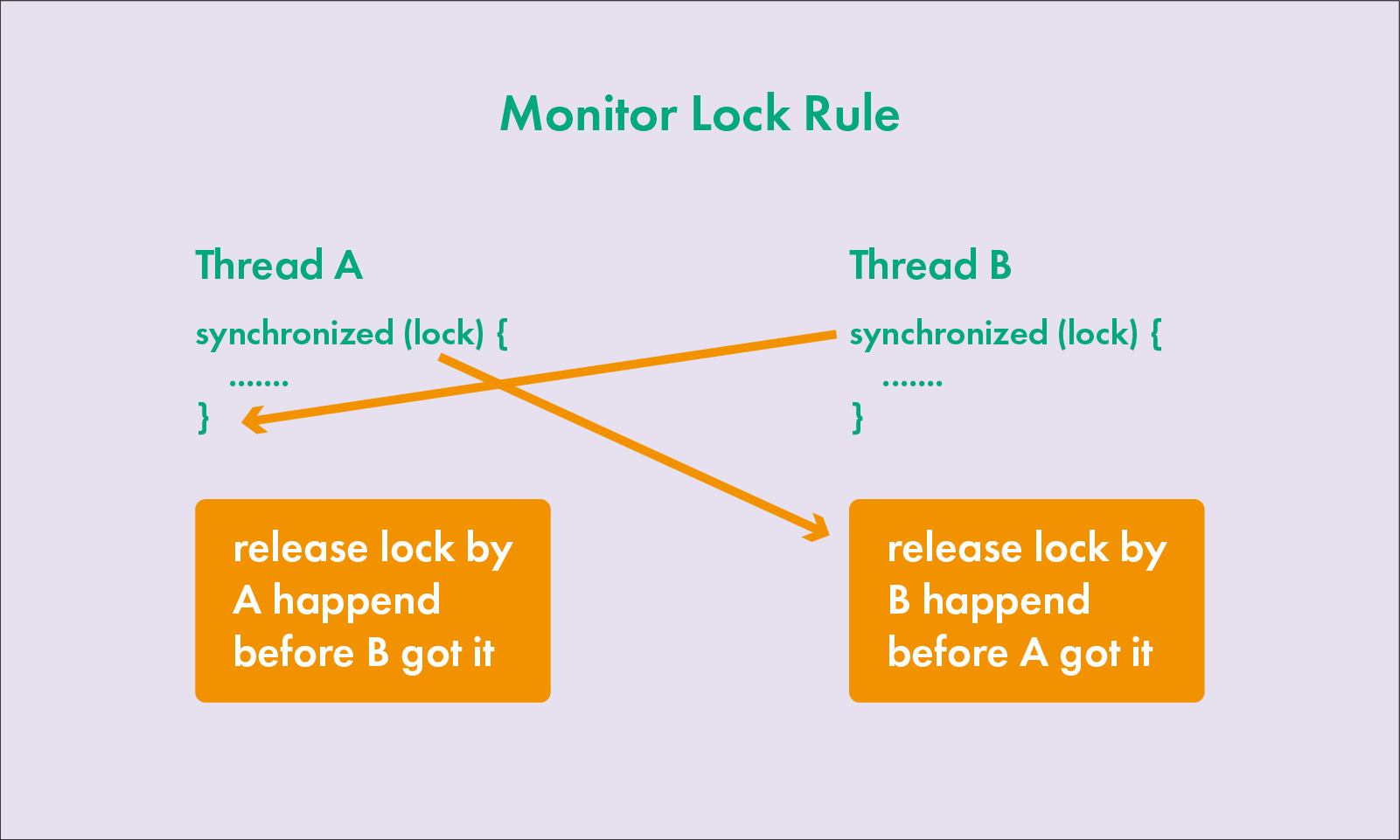
2. 监视器锁规则 Monitor Lock Rule
如果一个线程 A 加锁了,释放锁后,另一个线程 B 又拿到了这个锁,那么线程 A 之前的所有操作线程 B 都可以看到,也就是 unlock happened before lock
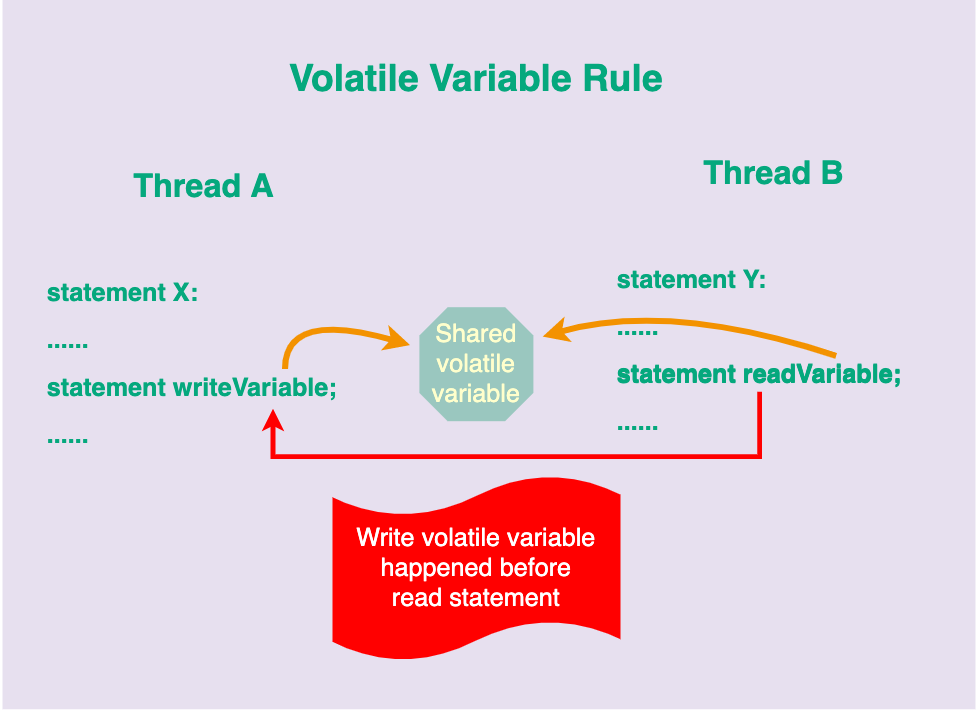
3. Volatile 变量规则 Volatile Variable Rule
如图,如果变量用 volatile 修饰,只要该变量有写入,那么读取这个变量的时候一定能读取到写入后的数据,也就是 写 happened beofre 读
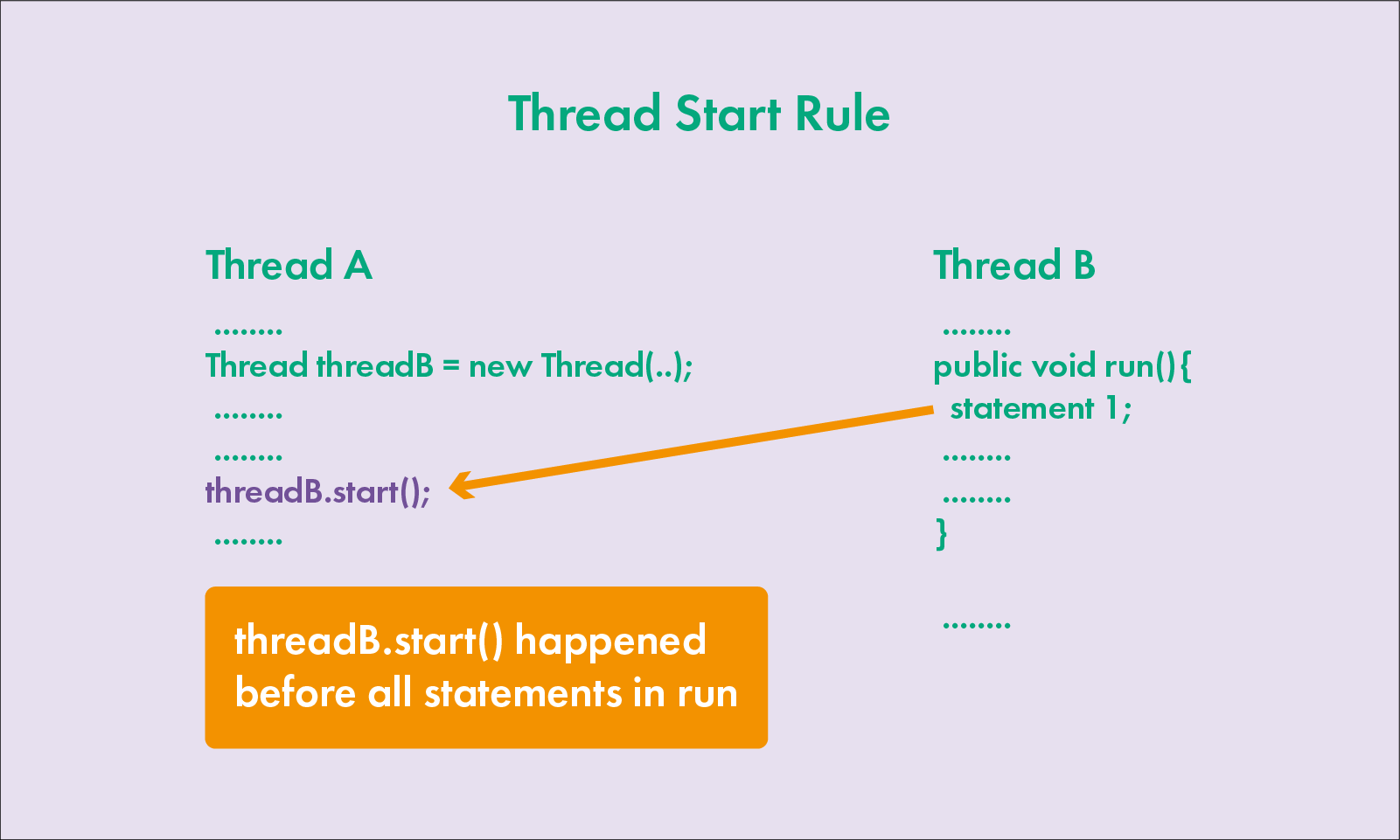
4. 线程启动规则 Thread Start Rule
在线程 A 中创建线程 B,并通过 start() 启动线程 B,那么线程 B 中 run 的代码可以看到线程 A 之前所有发生的结果,也就是 threadB.strat() happened before ThreadA
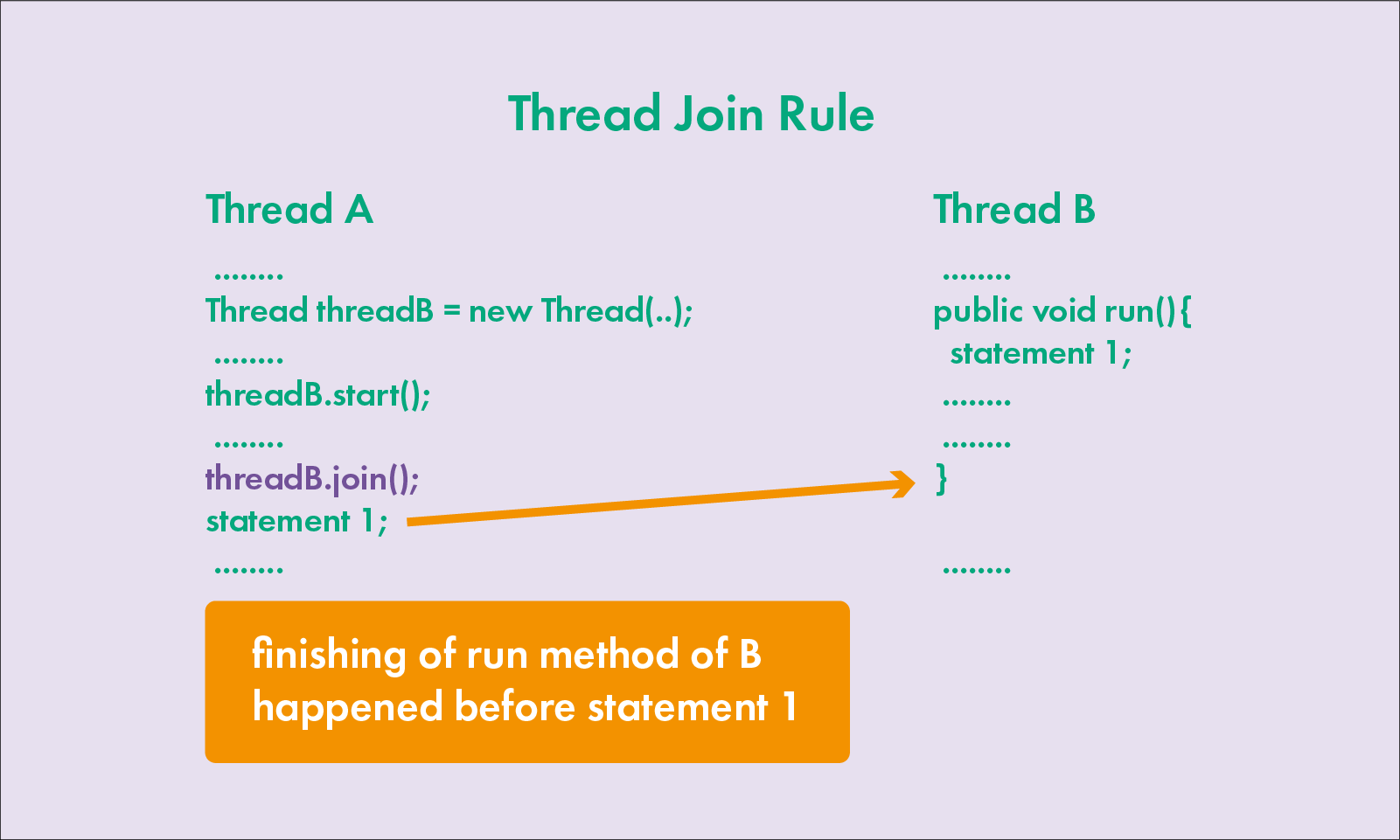
5. 线程 join 规则 Thread Join Rule
Thread A 调用 threadB.join(),那么 join 的下一句 statement 1 就能看到 Thread B 的操作,这样等 Thead B 执行完成后,才会继续执行 join 后面的语句。
6. 传递性 Transitivity
这个是基于 Single Thread Rule ,假如一个方法有 5 行代码,5 能看到 4,4 能看到 3, 3 能看到 2...... ,所以 5 也可以看到 1 ,4 也可以看到 1 。
7. 线程中断规则 Thread Interruption Rule
对线程的 interrupt () 的调用先行发生于线程的代码中检测到中断事件的发生,可以通过 Thread.interrupted() 方法检测是否发生中断。
8.对象终结规则 Finalizer Rule
一个对象的初始化完成 (构造函数执行结束) 先行发生于它的 finalize () 方法的开始。
意思就是:对象的 finalize () 方法能看到对象的构造方法的最后一条指令。